.svg)

The backbone of any AI-based tech model/platform is its data pipelines. These pipelines handle the collection, transformation, and delivery of data (whether it is training data of AI models or the information that needs to be processed by them) and their efficiency directly impacts the accuracy, speed, and performance of AI models. If data pipelines are inefficient, it can lead to poor performance of AI models, inaccurate predictions, slow decision-making, and missed opportunities. Thus, for the success of AI-based tech platforms, optimization of their data pipelines is crucial. Let’s understand through this blog the key components of a data pipeline that need to be optimized and the best practices to do so for enhanced performance of AI-based tech platforms.
Critical components of a data pipeline that need to be monitored and optimized
Understanding the core components of a data pipeline is essential for identifying areas that require optimization by data management experts. Data pipelines can have various stages (depending upon their use cases), but the three most critical processes in every data pipeline that need to be carefully monitored and optimized to ensure the optimal performance of the AI model are:
- Data ingestion/collection: It is the most critical and foundation stage of any data pipeline as it involves determining data sources and collating information from themfor further processing. To ensure that the appropriate data sources are identified and the relevant details are extracted, this stage requires careful monitoring.
- Data processing/transformation: At this stage, data gets cleansed, enriched, validated, and standardized to avoid errors, duplicates, and inconsistencies. Strict monitoring & optimization at this stage are crucial to ensure that AI models get accurate, complete, and structured data for further processing or analysis.
- Data storage: Processed data should be stored in a centralized database or warehouse for seamless and quick retrieval. It is important to monitor this stage to ensure that the data is stored in a secure and accessible location and in a format that is compatible with AI models.
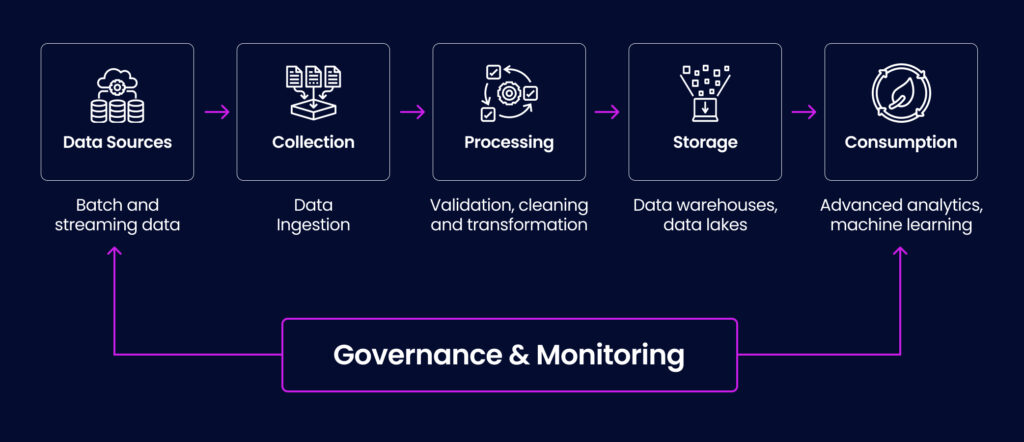
Key concerns to address with data pipeline management
What causes the data pipeline to become inefficient? There can be several factors responsible for it, but the most common or critical ones that you can address during data pipeline optimization are:
1. Poor data quality
Inefficient data pipelines are often caused by poor data quality. When data is collected from multiple sources, it is common to contain inaccuracies, duplicates or missing values, and inconsistencies. If this data is not cleaned, enriched, validated, and organized before being fed into AI models, it can lead to inaccurate and unreliable outputs.
2. Evolving data sources
Another key concern businesses face is managing rapidly evolving data sources. When new data sources are added to the system, data pipelines can be disrupted if they cannot adapt to schema changes or source system upgrades. Additionally, data from disparate sources often has different structures, which can cause data pipelines to fail if the data formats are incompatible.
3. Incomplete data scraping
Sometimes the issue is not with the data sources or formats but with the scraping tool. Data collection tools can extract incomplete information in some instances, either due to technical glitches or because the data fields are not clearly defined. This incomplete data can lead to disruptions in data pipelines and poorly performing AI models.
4. Operational or human error
Data pipelines can be disrupted by human or operational errors, especially in stages where automation is not possible or limited. This is because people working on data may not be subject matter experts or skilled, and they can easily make mistakes when labeling or entering data, leading to incorrectly trained AI models that perform poorly.
5. Lack of data privacy and security
Data privacy is a concern regardless of whether data is flowing through pipelines or stored in databases, especially when multi-user access is involved and the data is sensitive or confidential. If data is compromised at any stage of a pipeline, it can have severe consequences. Therefore, it is critical to implement robust data security measures at each stage of the data pipeline to maintain the integrity & confidentiality of sensitive information.
Effective strategies for data pipeline optimization
Now that you know the key areas to consider and address in data pipelines for AI-based platforms, let’s see how you can do it with the following proven strategies:
1. Verify & manage the data sources
It is crucial to validate and manage your data sources to ensure that complete, accurate, and up-to-date details are getting scraped for processing or training of AI models. Here are a few ways to do so:
- Extract data from only credible sources that transparently disclose their information collection practices for public use.
- Create a comprehensive catalog of all the data sources documenting all the critical details such as data format, update frequency, source location, ownership, and access restrictions.
- Utilize data profiling tools to analyze the structure and content of your data sources. This can help identify patterns, anomalies, and potential issues.
- Implement software mechanisms like CDC (change data capture) and data versioning to track the real-time changes in data sources.
2. Establish best practices for testing, validating, and monitoring data pipelines
Establishing an effective data governance framework is crucial to ensure that data pipelines produce high-quality output, reduce the risk of errors and inconsistencies, and support regulatory compliance requirements. Here are some best practices to do that:
- Evaluate data pipeline efficiency by setting performance benchmarks for key metrics like data throughput, latency, error rates, and processing times. Continuously monitor these metrics to detect anomalies and take proactive measures for maintaining data quality.
- Set up automated alerts to notify team members or concerned authorities when key metrics exceed potential thresholds for quick addressal & rectification of the issues.
- Adopt the best data cleansing strategies to identify and fix anomalies, missing values, and duplicates in the data.
- To identify and prevent recurring issues in the data pipeline, conduct a thorough root cause analysis. It will help to pinpoint the underlying causes of the problems.
- Implement robust data security measures to protect sensitive information. Clearly define data ownership and access, utilize firewalls and VPNs, and establish data usage policies for mitigating the risks of data breaches or cyber attacks at all stages of data pipelines.
- Apply data quality checks such as schema-based tests to validate the available information against predefined rules.
- Continuously review and update the data governance framework to adapt to technological advancements, address emerging challenges, and maintain the effectiveness of your data pipelines.
3. Parallelize data flow
When data volume starts growing, data pipelines may encounter performance bottlenecks if processing all the information sequentially. To overcome this, it is better to adopt parallel processing or distributed systems. It involves breaking down the larger datasets into smaller units for simultaneous processing by multiple processors to improve the efficiency of data pipelines and reduce their runtime. However, this approach is only useful for independent data flows, so you must thoroughly assess the data streams to determine their suitability for parallel processing.
4. Automate data testing & validation
Manually reviewing and finding anomalies & errors in the data can be quite time-consuming, especially when you are working on large datasets. By automating data testing, you can ensure the smooth functioning of the data pipeline and can identify issues in data quickly. There are several automated data validation tools, such as Ataccama One, Talend, and Astera that you can leverage to automate data testing at all stages of the data pipeline.
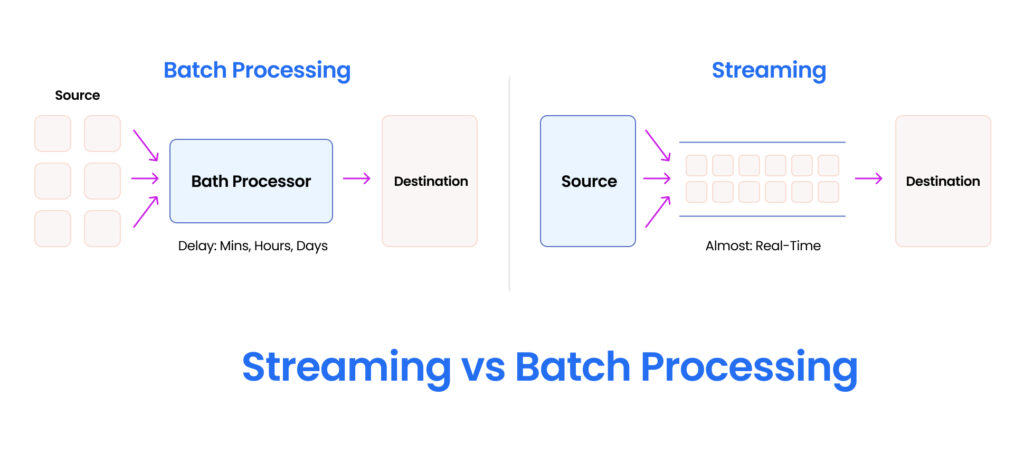
5. Utilize stream processing instead of batch processing
Stream processing offers several distinct advantages over batch processing, particularly for organizations that heavily depend on real-time data for making informed decisions. Unlike batch processing, which involves collecting and processing data in predetermined intervals, stream processing enables the continuous transformation of data as it is generated. This real-time data processing capability empowers organizations to significantly reduce data latency and identify errors/issues in data pipelines at initial stages.
Let’s understand it with an example:
An eCommerce platform experiences a surge in online transactions during a major sales event.
Batch processing approach:
- Transaction data is collected and stored throughout the sales event.
- Once the sales event concludes, the accumulated transaction data is processed during a scheduled batch job.
- The processed data is then analyzed to identify patterns, trends, and potential fraud.
Stream processing approach:
- Transaction data is processed as it occurs, in real time.
- Fraud detection algorithms are continuously applied to the incoming data stream, enabling the platform to identify and flag potentially fraudulent transactions immediately.
- This real-time fraud detection capability allows the platform to take immediate action to prevent fraudulent transactions from being completed, minimizing financial losses and protecting customers.
6. Leverage human-in-the-loop approach
While automation can make the identification of errors & anomalies in data quick and seamless, it is better to rely on human experts for rectification of issues in datasets. The human-in-the-loop approach can be introduced in several aspects of data pipelines, such as:
- Data cleansing & validation: While automated tools can effectively detect outliers in datasets, human data experts can often identify additional outliers that tools might miss. Automated tools rely on predefined algorithms and parameters, which can sometimes lead to outliers being overlooked. Human experts, on the other hand, can leverage their understanding of the data and context to identify outliers that may not conform to the expected range or patterns.
Additionally, upon identifying an error or inconsistency in the data, human experts can also explain why they believe that the data is incorrect. This information can help identify the root cause of the error and prevent similar errors from occurring in the future.
- Data enrichment: While automated tools can easily identify the missing details in datasets, human experts can better append those missing details by conducting thorough research. Leveraging their knowledge and subject matter expertise, they can enrich data with accurate and relevant information for improving the efficiency of data pipelines and AI models.
Short of subject matter experts for data quality management?
Let us be your helping hand!
Key takeaway
Optimizing data pipelines is crucial for the success of AI-powered tech platforms. By implementing the strategies and techniques discussed in this blog, organizations can ensure that their data pipelines are efficient, scalable, and cost-effective, leading to improved AI model performance, reduced latency, and enhanced operational outcomes. As data volumes continue to grow and AI applications become increasingly sophisticated, the ability to optimize data pipelines will be a critical differentiator for organizations striving to achieve AI-driven innovation.
Brought to you by the Marketing & Communications Team at SunTec Data. On this platform, we share our passion for Data Intelligence as well as our opinions on the latest trends in Data Processing & Support Services.

