.svg)

How High-quality Training Data Improves AI/ML Models’ Accuracy
Understand why high-quality labeled datasets are a must for successful computer vision models.
The accuracy of an AI/ML model depends on the quality of its training data- the fuel that drives its efficiency. If the training data is not accurately annotated, the model will not be able to provide correct outcomes. While data annotation is an important part of AI/ML model development for businesses, its process is not straightforward. There are various types of data annotation for training different models for specific use cases. Additionally, challenges like data biases, acquiring high-quality training data, and limited resources & expertise must be addressed for efficient data annotation. Let’s understand the significance of data annotation along with its types and challenges to build better AI and ML models through this guide.
What Are the Types of Data Annotation Required for AI/ML Models Training?
The types of labeled data required for the training of AI or ML models depend on what you want to accomplish from them. There are three major types of data annotation:
1. Text Annotation for Natural Language Processing

Image Source
Text annotation involves adding metadata or labels to text data for training AI/ML models to understand human language, intent, or emotions. It is used for NLP models, AI chatbots, information extraction, and improving text readability. Some common types of text annotation are:
- Text Classification: Assigning labels or categories to a given text document.
- Named Entity Recognition (NER): Identifying and categorizing entities (e.g., names, locations) within a text.
- Part-of-Speech (POS) Tagging: Labeling words in a sentence with its part of speech (noun, verb, etc.).
- Sentiment Analysis: Determining the sentiment or emotion expressed in a text.
- Intent Analysis: Analyzing the user’s intent or purpose and labeling the text accordingly.
- Semantic Analysis: Identifying the relationships between different entities in the text.
2. Video Annotation for Accurate Visualization Training

In video annotation, visual clips are labeled frame-by-frame for training computer vision models to detect and recognize moving objects accurately. It involves:
- Action Recognition: Identifying and classifying activities within a video.
- Object Tracking: Movement tracking of specific objects across different frames of a video.
- Event Detection: Labeling specific events or occurrences within a video.
3. Image Annotation for Object Detection & Identification
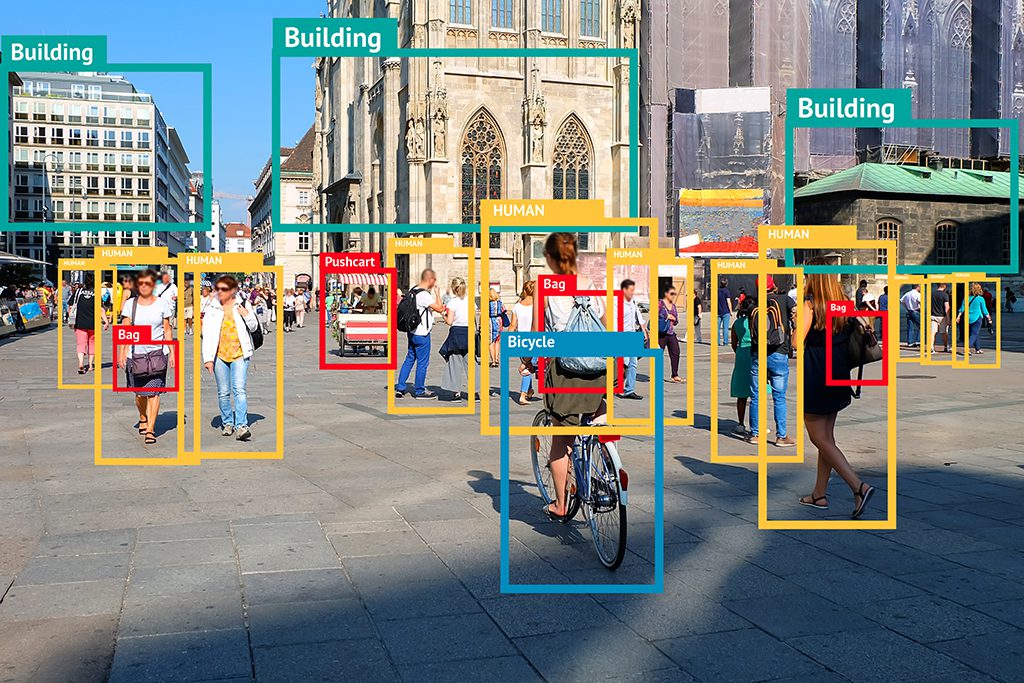
Image Source
In image annotation, specific objects of interest in a picture can be labeled for the visual perception of the AI and ML models. Various techniques can be used for image annotation, such as:
- Bounding Boxes: For drawing rectangles around objects of interest in an image.
- Semantic Segmentation: Assigning a label to each pixel in an image to segment objects or regions.
- Instance Segmentation: Individually labeling the different instances of the same object.
- Landmarking: Marking specific points within an image (for example, labeling facial features)
- Polygon: Drawing boundaries around the specific object in an image
How High-quality Annotated Data Helps?
If the training dataset is of high quality, it will improve the accuracy and reliability of AI models in various ways. Some of the benefits of having high-quality training datasets are listed below.
- Better Model Training: Accurate training data helps AI models identify relationships and generate understanding. This reduces the chances of prediction errors and improves the overall efficiency of the model.
- Natural Language Understanding: NLU allows AI models to learn and interpret human language better. High-quality annotated data helps language models to correctly establish relationships between words, phrases, and concepts for better contextual understanding.
- Save Time and Money: AI/ML models trained on high-quality data require fewer improvements in performance. So, companies can quickly deploy the models trained on such data and less money is spent on retraining and re-annotating data.
- Enhanced Reliability and Adoption: High-quality training datasets help in creating more efficient and reliable AI/ML models, which can be easily and widely adopted by users for various purposes.
- Improved Predictions: When AI models are trained on high-quality annotated data, they better understand how to respond in real-world situations. It enhances their capability to provide more accurate predictions for unseen data.
What Are the Challenges of Data Annotation for AI & ML Companies?
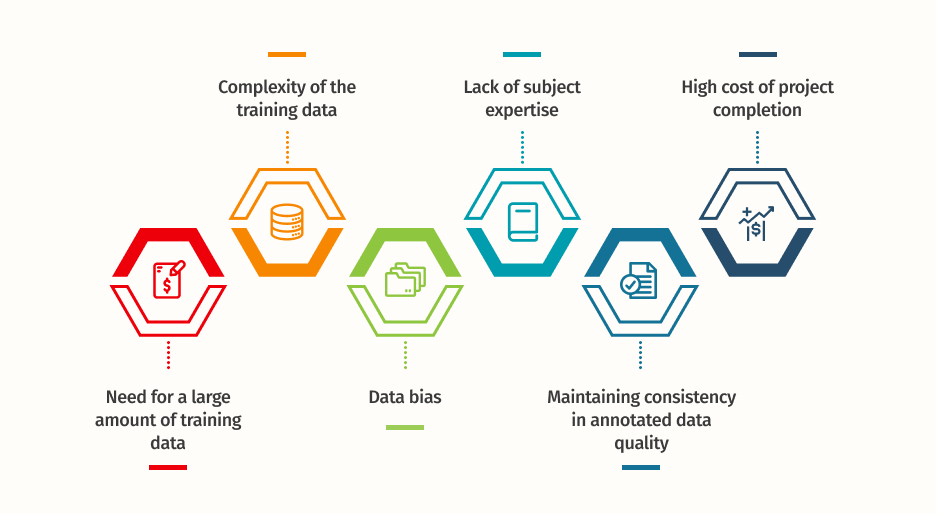
The various challenges involved in data annotation make the process difficult and time-consuming. These key issues need to be addressed for the efficient performance of the AI & ML models.
1. Need for a Large Amount of High-quality Training Data
AI and ML models are always hungry for large amounts of high-quality training data. For their effective training and efficient performance, organizations require a constant supply of diverse and accurately labeled data, which is a cost and time-consuming affair. Not having the right amount of training data can slow down development and make it difficult to get the models to the market on time.
2. The Complexity of the Training Data
Complex datasets can contain a large number of data points, making it difficult to identify which ones to label. Additionally, if the datasets are too complex to understand, it will be challenging for annotators to assign correct labels, which can lead to poor predictions by the AI & ML models.
3. Lack of Subject Expertise
To pick the right data for training AI/ML models, identify the important data points, and handle missing data, organizations require subject matter experts. Utilizing their domain knowledge, they can ensure that the model is trained on the right data. Without them, organizations would end up developing language models that are not effective or do not meet the needs of the business.
4. Data Bias
Bias is one of the most significant and common challenges in data annotation. The subjective interpretation of data annotators can introduce bias in the datasets, leading to inaccurate predictions by AI models. Human bias can be introduced due to the limited knowledge or opinion-based understanding of certain concepts by annotators. Additionally, when AI models are trained on data that does not represent the whole population, it can reinforce sampling biases.
5. High Cost of Project Completion
Data annotation can be an expensive affair for companies, as they require experienced data annotators, cutting-edge data annotation tools & technologies, and large amounts of high-quality labeled data to efficiently train the AI/ML models.
6. Maintaining Consistency in the Quality of the Annotated Data
Achieving consistency in the quality of the training data is essential for the optimal efficiency of AI models. However, it can be challenging for organizations if the data annotation guidelines are not clear or the data is ambiguous.
How to Improve the Quality of Data Annotation?
The quality of your training data is critical to the performance of your AI model. High-quality data can help your model learn more effectively and make better predictions.
Here are some best practices for improving data quality:
Set Clear Guidelines
To avoid the subjective interpretation of information by different annotators, keep the data annotation guidelines clear and concise. You can provide samples of correctly and incorrectly annotated data to help annotators understand the criteria for accurate labeling. If there are any domain-specific terms or requirements, they should be denoted through the trained datasets to avoid incorrect predictions.
Employ Expert Data Annotators
It is crucial to hire experienced data annotators with the right skill set and domain knowledge for the effective training of your AI model. Experienced annotators can understand complex terms better and label the data more accurately for efficient model performance.
If you don’t have the budget, infrastructure, or time to hire and train your annotators, you can outsource data annotation services to a reliable third-party provider. These providers have the expertise to handle your requirements within your budget and timeframe.
Implement Data Quality Measures
To achieve the desired level of efficiency for your AI model, it is crucial to set performance benchmarks. If the model is not able to meet those benchmarks, then the quality of the training dataset can be improved for better outcomes.
Additionally, to minimize human errors and biases, assign annotations for the same data to multiple annotators. This allows you to compare the annotations and identify any areas where there is disagreement or inconsistency. You can then resolve these issues and ensure that the annotations are as accurate as possible.
Evaluate the Quality of Training Data at Multiple Stages
The labeled data must be continuously evaluated as we collect it, annotate it, and use it for training the model. This will help you to identify any problems with the data early on and make necessary adjustments.
Leverage Data Annotation Tools
To streamline the annotation process and maintain quality, invest in cutting-edge data annotation tools and platforms, such as LabelBox, CVAT, Appen, and CrowdAI. These tools provide useful collaboration features, such as annotation history, version control, and much more to make the labeling of various data types easy for annotators.
Conclusion
Accurately labeled data is critical to the success of any predictive AI or ML model. For efficient performance and predictions, AI/ML models must be fed on high-quality data. To overcome challenges like lack of quality training data and data bias, organizations must invest in experienced data annotators, advanced infrastructure, and robust data quality processes. By doing so, businesses can ensure that their AI models are built on a foundation of quality data, which will lead to better outcomes. The future of data annotation and AI model development is bright, and organizations that can master data annotation will be well-positioned to succeed in the AI era.
FAQs
1. Why is data annotation important for the training of AI and ML models?
Data annotation determines what type of data the AI or ML model will be trained upon. By labeling and classifying datasets, it bridges the gap between the raw data & meaningful insights and helps AL/ML models to make accurate predictions based on the high-quality tags used for training them.
2. Can data annotation be automated?
Yes! Data annotation can be automated through AI-based software and tools. These tools can annotate large amounts of raw data by learning from existing samples and can also help in improving the quality of training data for improved outcomes.
3. Does more training data increase model accuracy?
Yes, but only when the labeled data is relevant and of high quality. AI or ML models understand and identify patterns based on the dataset they are trained upon. More diverse and reliable training data provides them with a better contextual understanding of a certain topic or domain, enabling them to make more accurate predictions.
4. What are the data privacy considerations when outsourcing data annotation tasks to third-party service providers?
When outsourcing data annotation services, consider the following points:
1. Service-level agreements: Check if they sign service-level agreements to maintain the confidentiality of your data.
2. Data security measures: Evaluate their data security protocols, such as the usage of VPN, authorized access, and data handling policies.
3. Data security compliances: Check if they possess any ISO certifications for data security.
By considering these factors, you can easily select a provider with the expertise and experience to safeguard your data effectively.
5. What is the main difference in data annotation requirements between supervised and unsupervised learning models?
Supervised learning models require labeled data, while unsupervised learning models can find hidden patterns and insights from the given data. Therefore, expert data annotators are required to correctly label the training data for supervised models, while for unsupervised models, the need for human intervention is minimal.
Brought to you by the Marketing & Communications Team at SunTec Data. On this platform, we share our passion for Data Intelligence as well as our opinions on the latest trends in Data Processing & Support Services.

